a blog by Peter Leonard


A while back I posted about trying to collect a full run of the print edition of MacWEEK, a tabloid-sized weekly publication printed between 1987 and 1998. (A cross-platform reboot, eMediaweekly, lasted from August of 1998 to February of 1999.)

The ultimate goal of this was more than filling up bookshelves with heavy paper, although that happened as well. As one might observe from my work with Vogue, I think that periodicals are a fascinating place to observe change over time. All told, there were nearly 34,000 articles and reviews published in MacWEEK over its ten-year publishing run.
Interestingly, I spent quite a bit of time de-duplicating articles that were published both in print and online. I’m now pretty confident I have that sorted; my decision was to keep the print variant, as it often benefited from additional editing or review. (One would think the opposite could be true — if breaking news caused an important change to be reflected online after the print deadline. But, as far as I can tell, the website sort of ‘broke’ news and then the print edition got slightly refined prose a week later.)
34,000 articles is obviously way too many to read and retain any significant information about. But it’s a perfect amount of information to use an approach that asks data to “organize itself.” Though it might sound improbable, using nothing more than term co-occurrence (the company a word keeps), we can see some pretty strong patterns emerge. Here’s an example of what we can do with topic modeling: two distinct topics (in a 50-topic model), both about hypertext. Even without the labels or time charts, it’s pretty easy to guess what they’re about from their words alone:

Articles have covered the connections between this 1987 hypertext platform and what would emerge nearly a decade later as the World Wide Web. MacWEEK’s print run just happens to nicely catch both the introduction of HyperCard and the runup to dot-com madness in the 1990s.
I’d like to explore the overlap in vocabulary between these two topics — as we recall, topic models are probability distributions over every term in the corpus, not just the 15 words shown in the visualizations above. My best guess is that “link” or “hypertext” would occur in both.
The notion of terms reoccurring in multiple discourses is of course a strength of topic modeling, as opposed to other approaches where words must be clustered or categorized with one mutually-exclusive label. Normally we demonstrate this with examples such as “bank”, which we might expect to occur in both financial and ecological topics. But there’s another way to think about words in topics, which is their ranking in topics which themselves are bound in time.
Here I’m sort of making a virtue out of necessity: I haven’t had time yet to explore
some really exiting advances in topic modeling theory and implementations, including
topics over time and dynamic topic modeling.
With such an exquisitely date-stamped corpus (the magazine is literally called MacWEEK),
I really need to step beyond vanilla Mallet and explore methods that model diachronic change.
But for now, I’d like to explore how the word “internet” behaves (in a very simplistic sense) in a number of topics related to computer networking.

I’ve presented these four topics not in order of their chronological spread (although one could compute that) but instead by how important the word internet is in each one.

It’s no surprise that the topic I labeled “WWW” has internet as its second-ranking term, just after web. For many people, the World Wide Web was the internet, and no amount of footnotes about usenet, gopher, wais or other earlier protocols would change that. internet belongs right at the top in recognition of how the Web was the internet’s first “killer app”. (If you’re wondering what the “ProVUE Development” article is about, they made an early graphical HTML builder program.)
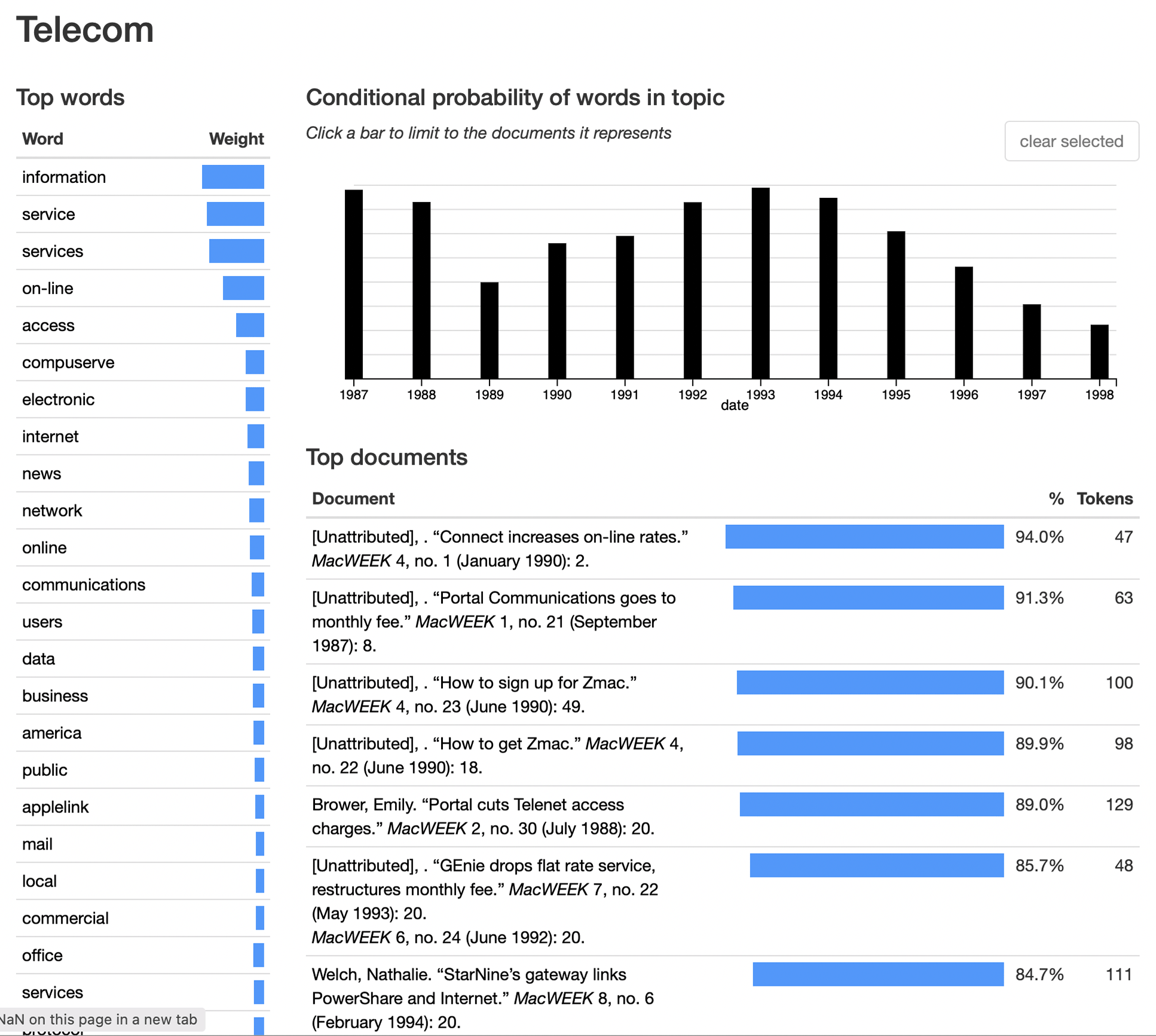
Let’s move down to the second column, which I labeled “Telecom” but actually think I should rename “pre-broadband dial-up services”. This is a topic about getting online, which, before broadband meant, modems. There’s a mix of pre-internet services, such as Apple’s own AppleLink, CompuServe, and probably the constituent words of America Online. Other words here include the bare mechanics of getting online during this era: phone, hours, charges, cost and fee. Easy to forget how ‘metered’ access was during this era. Again, I haven’t even looked at the time spread of this topic — I’m mostly interested in where internet falls in the discourse, which is near, but not at, the top. There’s probably some interesting work here in figuring out exactly when services such as Compuserve and AOL stopped being mainly about their own proprietary forums and resources, and started to be an easy way to bridge out to the broader internet. (Indeed, even 1980s bulletin board systems often offered this kind of ‘internet gateway’ functionality, at least for email.)
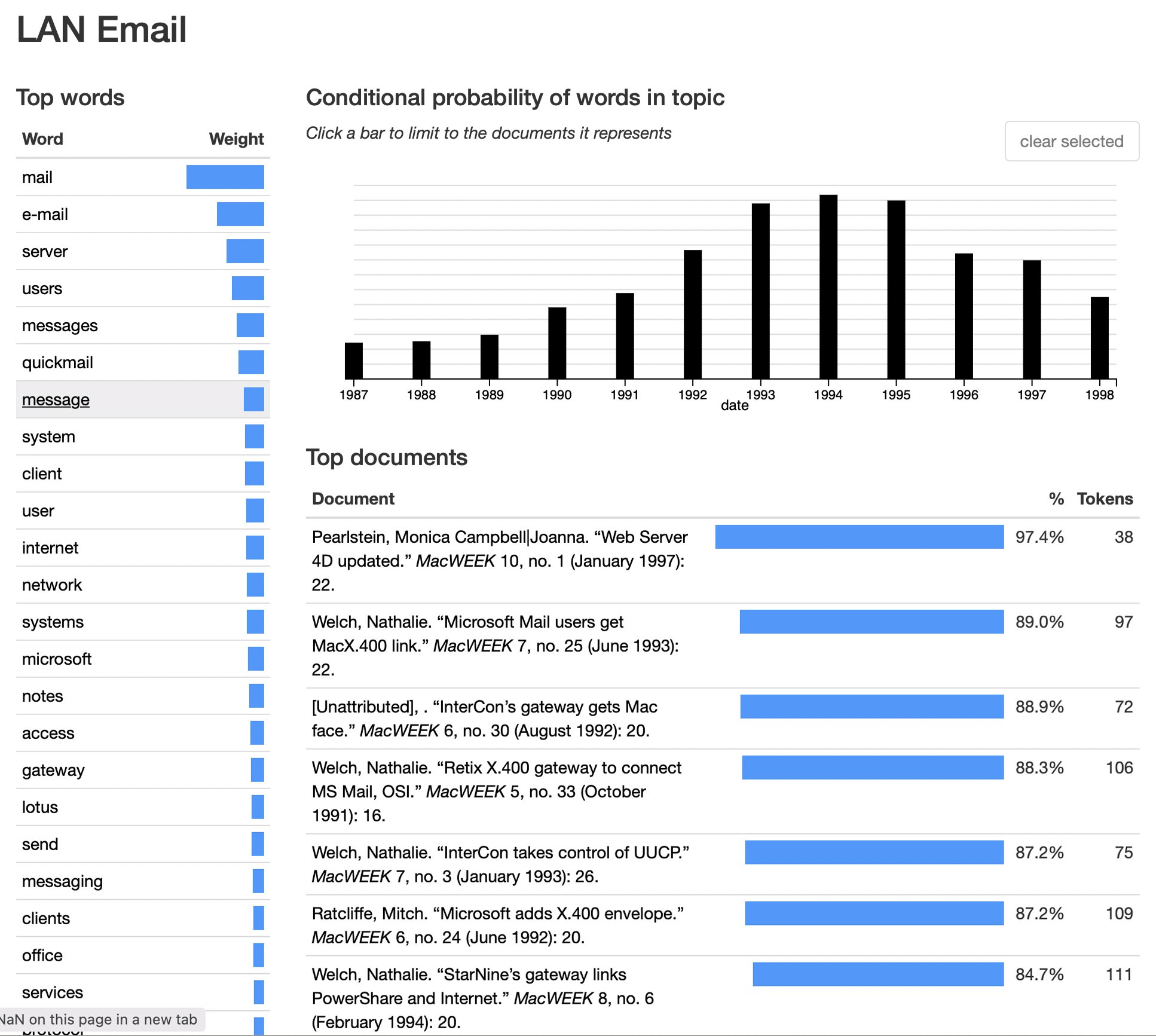
The third topic I’ve labelled “LAN Email”. This is partially, I think, an artifact of what MacWEEK covered: corporate networks, the software and hardware required to install and manage then, and what you could do with them. It’s no surprise to see QuickMail here, as CE Software’s package was a standard in early Mac networking. Lotus Notes, and even Apple’s failed PowerTalk make an appearance as well. internet is prominent here as well, albeit a little lower down on the list than it was for “pre-broadband dial-up services”. Still, terms such as unix and gateway point to the importance of exchanging email beyond your own company. (An additional note: before the notion of The Internet, “internet” was a generic term describing connections between LANs, which would be entirely appropriate to this topic of corporate networking.)
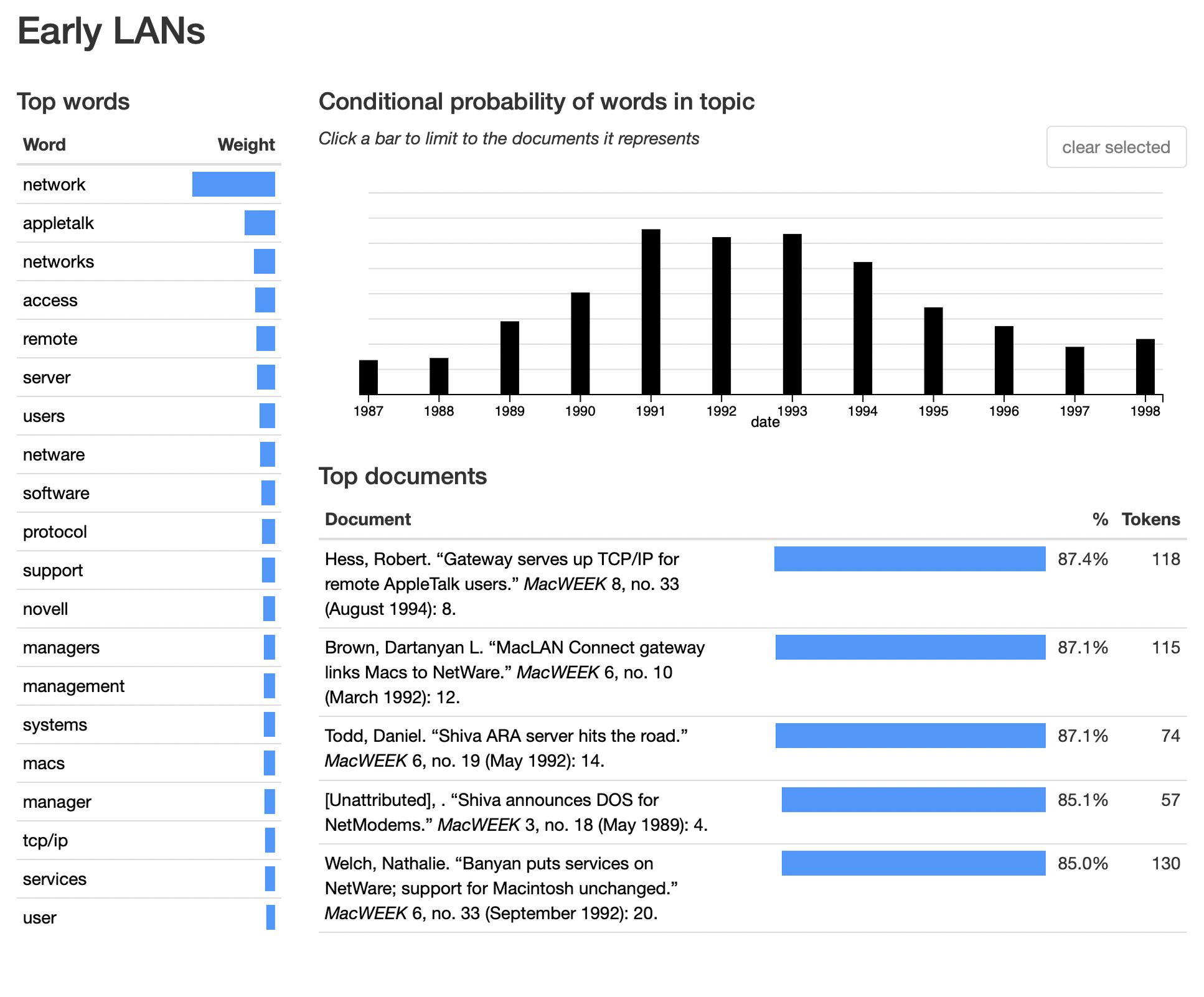
Finally, we have a topic I’m calling “Early LANs”. This is close to the topic above, but with less of an emphasis on messaging and more on the basics of getting these networks up and running in this highly confusing and pre-standards era. novell and netware gesture to the era we’re in, as does ara: together with that acronym’s constituent words, it refers to AppleTalk Remote Access: a way of dialing in via modem to a corporate network while on the road. shiva was a big vendor for LocalTalk hubs and routers, and we also see Farallon’s timbuktu screen-sharing software (the Zoom screen share of 1988!). internet is here too, but probably mostly in the former sense of the word, connecting multiple networks.
Amidst all these examples of change, it’s interesting to look at continuities as well. The very obvious “storage” topic is kind of steady-state all the way from the beginning, in 1987:
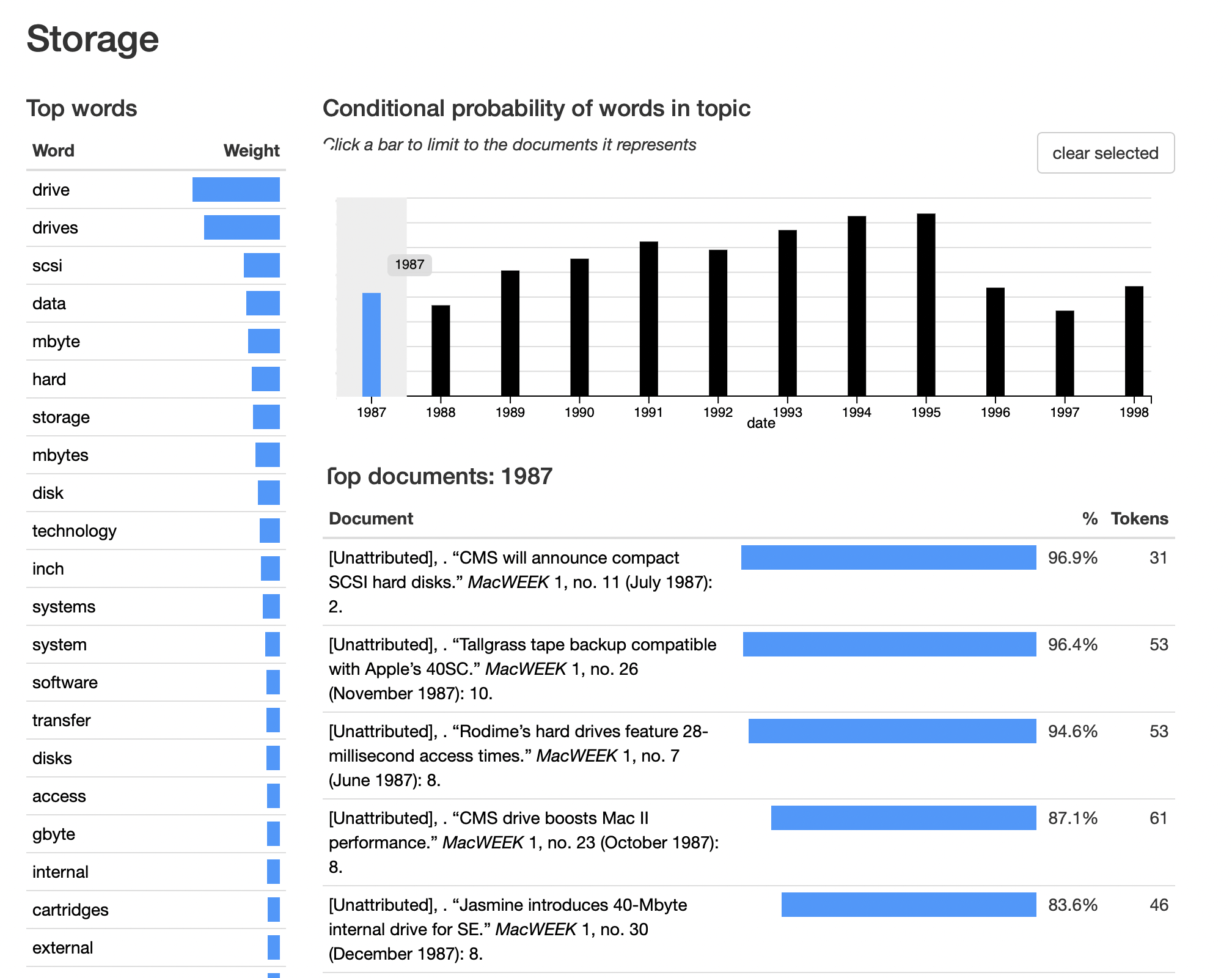
I should point out that 1987 was after SCSI had been introduced, in January 1986 with the Mac Plus. So it’s possible adding in earlier publications would trigger a preceding “proprietary and serial hard drive storage” topic, full of evolutionary dead ends such as the HyperDrive.
Some will recognize the screenshots above as coming from Andrew Goldstone’s excellent dfr-browser software, which does such an admirable job of presenting both topics at scale:
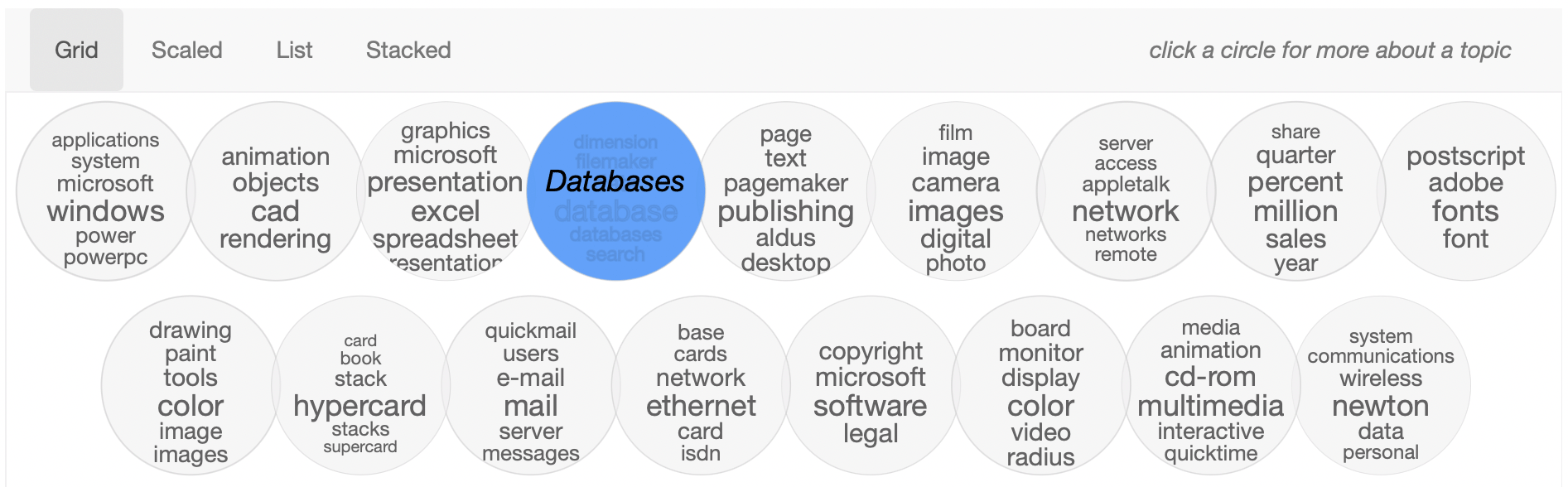
… but also the the crucial workflow of doing close reading to see what the constituent articles are actually about:
Still, there are some user affordances that would make exploring a model even easier and more rewarding. One I can imagine would be linking words in a model to a KWIC view of that particular term as expressed in articles highly saturated for that topic. This would allow us to explore what exactly “internet” meant in the Early LANs vs Telecom topic, for example. I can imagine ways to do this with a separate corpus query engine, such as Philologic, but I think recent work from Chicago on the Intertextual Hub is actually moving in this direction. See, for example, the example page for the French word abbe. Ironically, a deep-link to a KWIC list of documents is about the only feature I can’t find on that page, but it may be possible that I’m missing something.
A final note: the standard disclaimers about topic modeling apply here. My choice of 50 topics plays a significant role in how the discourse in these 34,000 articles is presented. Insisting on a unreasonably smaller number, such as 10, would no doubt squish Atkinson’s and Berners-Lee’s software together, and lose the nuance of the slow fade of HyperCard years before the explosive growth of the web.