a blog by Peter Leonard


I started writing this post about making order-of-magnitude estimates, but it turned into more of a question of what counts as a “hit” when we search through scanned books.
Part I: Estimating Numbers
A few months back I had a question: how many volumes does Google Books actually have in the mainland Nordic languages?
It turns out answering this question is a little tricky. While you can constrain a query to a given language in the “Advanced Search” function of Google Books, you can’t just return a list of all books in that language. If you try to leave the “Search For” field blank, in an attempt to return a list of all books, you just get redirected to the home page of google.com, with nary an apology. So you have to search for something — anything — that will trigger at least one hit per book.
What can we search for that will be in every published volume in a language? The words for “I” wouldn’t necessarily work — there might be a history book without any dialogue. Searching for “said” would return nearly every novel, but very few plays.
What I settled on was to search for indefinite articles — the equivalent of “a” and “an” in English. (Definite articles in these languages are suffixed onto the noun, so that wouldn’t work.) Modern Nordic languages (except some kinds of Norwegian) have two grammatical genders, endearingly called neutrum and utrum in Swedish, or neuter and common-gender. (Yes, in the Swedish language at least, gender has indeed collapsed.) With some minor orthographic variations, these work out to “en” and “ett” in most cases. To sum up: if we search on either of these two words, we should get our one required hit in 99.999% of all texts.
(As an aside, you may wonder whether searching for one indefinite article or the other influences the search results. The answer is it does, but at very small levels that I suspect may be noise, or slightly-out-of-date indexes.)
To generate a quick and dirty graph, I chose to chunk the results in decade-long sections. I figured this would give me a sense of change over time, without making me do 100 separate queries times three languages.
So! What are the results of this admittedly unscientific survey?
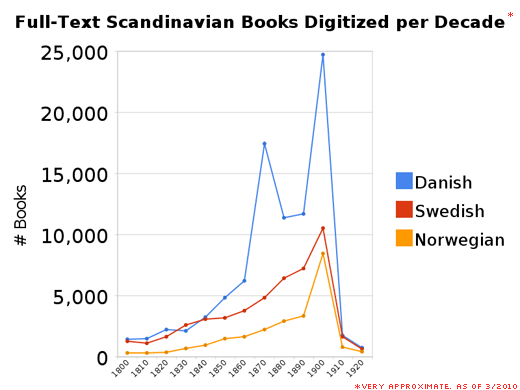
First off, we should say that all publishing does not cease in Scandinavia around 1920. I restricted my queries to full-text-available only, which essentially means no longer in copyright. Between libraries’ decisions to only scan out-of-copyright texts, and the search engine obeying my command to only display full-text books, the data just appears to go to zero.
Secondly, the question of which collections these books came from. In spot checking some of these results, I’ve found books from everywhere from Harvard to the NYPL to the Bavarian State Library. But we also know that the Royal Library in Denmark (which serves as both the national library as well as the library of the University of Copenhagen) has an agreement with Google Books to digitize parts of its collections. (See this presentation for more details.) So the very noticeable spikes in the Danish material may be an artifact of one library giving Google everything from 1900-1910 as a test, for example. We would need to compare this graphs to an actual history of publishing in the three Nordic countries to know how well it maps to what was actually printed.
All told, however, my results seem to suggest that Google Books had roughly 160,000 full-text volumes in Norwegian, Danish and Swedish as of March 2010. Keep in mind, that’s texts of all types, including things like church records, some serials, and no doubt a lot of ephemera.
Part II: Results and Context
In the time since I did this quick and dirty analysis, Google has deployed a refinement in their search system — an attempt to weld together their discrete searches for media such as videos, images, books, status updates, etc. But this change has had a negative effect on our ability do conduct even approximate counting such as that shown in the graph above.
Most commonly called “The New Sidebar” in online discussions, this feature seemed to deploy in a distributed fashion between November 2009 and May 2010. Either as part of this update, or during roughly the same timeframe, Google Books stopped counting the number of volumes with a given word you searched for, and started counting the number of hits. So for example I can now tell you that the word “en” was used 83,000 times in Swedish-language books in the year 1900, but I can’t tell you how many books that represents. (Clearly, Sweden did not publish 227 books every day that year, or I would have never gotten through my General Exam reading list.)
The new system is, undoubtably, more useful for certain things — like finding the frequency of term occurrence over time. But unless I’m missing some big obvious button somewhere, we have lost the ability to count works that include a word or phrase. The only way we can get the total number of works, it seems, would be to go to the end of all the results page for each query, count the total pages and then multiply by 10, for the number of results on every page.
Finally, it’s worth noting that the accuracy of any of Google Books’ metadata has been the subject of some debate. Even when the system reported the number of works with a given search term, such as the chart above, I was trusting both the publication date as well as the language fields. Geoff Nunberg’s investigation and critique of precisely these fields has received a lot of attention last year, however what I’ll link to is the interesting post by Google’s Jon Orwant in the comments section below. My feeling is that in my own field, Scandinavian Literature, we may be facing questions of metadata quality that are as-of-yet unexposed, because of the much smaller number of people who read these languages compared to English.
Still, there’ no doubt that eventually Google Books will be a scholarly resource of first measure, irrespective of whether it was originally intended to be or, indeed, is presently run to be. What will help is input and feedback from people working in literature (and corpus linguistics, to name a field with several decades’ more experience with problems like these.) Sussing out what constitutes a “hit” — linguistic lemma or published volume — is one of the more interesting questions we’ll all have to think about in the future.